Longread
Digital twins, what are they?
Artificial intelligence, sensor technology, data science and other types of numerical simulations are IT technologies with great potential in the practice of the fresh supply chain. Not only each technology on its own, but also these technologies combined. When we combine them with product and supply chain knowledge, we can create digital twins of the fresh supply chain.
What is a digital twin?
Many different definitions of digital twins exist. We typically follow the definition given in the Gartner Glossary of Information Technology:
Definition: “A digital twin is a digital representation of a real-world entity or system. The implementation of a digital twin is an encapsulated software object or model that mirrors a unique physical object, process, organization, person or other abstraction. Data from multiple digital twins can be aggregated for a composite view across a number of real-world entities, such as power plants or a city, and their related processes”
That is a whole mouthful for a definition. But what does it mean in the real world?
First “a digital representation of a real-world entity”. It means that a real object, like a banana, a reefer container, a truck, or even the supply chain as a whole is observed very well, and the data gathered during this observation are stored in a computer or cloud environment. These data can be used to show the state of the object. Note that a digital representation is never as complex or as accurate as the real-world object itself. The figure below illustrates this.

Second “a digital twin is a software object that mirrors a unique physical object”. This means that not only the observed data are stored in the computer, but that software is created that uses these data to make a model. This can be a mathematical, physical, statistical, or data-driven model. Such a model can be used to simulate the effects of time and conditions on the real-world product, and predict what will happen in different scenarios. If for example a software object of a reefer container is created in which the air temperature distribution is modelled, it is easy to play around with different air speeds and inlet air temperatures to see how the temperature distribution of the real-world reefer container would be under these circumstances. The big advantage is that you do not need to have all the settings tested and measured in real-life, it can be done with a computer! That is much more convenient, saving time and resources. The figure below shows the air distribution inside a reefer container. Please note, though, that such physics-based models in this figure are already used for several decades in engineering to test the impact of different parameters, and are not in themselves digital twins. In order for the twin to mirror the unique physical object, a connection of the model to that unique shipment in the reefer container is required. This connection can be made, for example, by feeding the model with (near) real-time sensor data of that particular shipment. That way the twin in the computer will respond in a different way for every single shipment; the digital and physical
shipments become true twins.

Last, the definition states that “data from different digital twins can be aggregated for a composite view”. Here, we can think of a load of bananas in a reefer container. The digital twin of the banana will predict the ripening and softening of the banana tissue. The digital twin of the reefer will predict temperature, humidity and metabolic gas distribution. Both digital twins have interactions since air temperature and humidity are important factors in ripening and softening.
How to create a digital twin?
Typically five steps are needed to create a digital twin:
Step 1: Have the right sensors in place
Think of which aspects of the object you want to monitor and which sensors could contribute to this in order to link the twin to the real world. It is important to place the sensors at a location where they give a representative value. The number of sensors should be considered as well to get a proper measurement.
Besides the type of measurements, it is also important to think of the frequency of the measurements. How often does the sensor need to gather data, and how often does the sensor need to send the data to a database. Will your digital twin respond in real-time, is there a delay, and how long can this be?
Step 2: Gather high-quality data
The data from the sensors are stored in a database. Perhaps manually recorded data such as a checklist is added as well. Some numerical data will not be sent by the sensors, but need to be collected from the sensors.
In this step, the quality of the data is essential. Outliers need to be identified and discarded. The units of data have to be checked before data can be combined. Important is also that the start of the twin simulations and its initial conditions are matched to the sensor data. Sensors usually start logging earlier and only stop logging after the shipment has arrived.
Step 3: Create models that represent the behaviour of the real-world object
Models are simplified representations of reality. A model can be physics-based, where e.g. the ripening of the banana is modelled according to our understanding of the underlying physiological processes in the banana or the heat and mass balance inside a cold storage or reefer container. A model can also be data-driven, e.g. a deep learning model. Simple statistics-based twins can also be used, relying on regression models, for example.
Step 4: Implement the software to bring (sensor)data and models together
To have a composite and comprehensive digital twin, e.g. a load of bananas in a reefer container during transport, sensors, data and models need to work together. The software to make this happen can be partly off-shelf software, but often must be custom-made.
When implementing the software, it is important to know how to deal with unforeseen circumstances, such as missing data because of a lack of internet connection, faulty data because of incorrectly placed sensors, or erroneous model outcomes because of out-of-spec data (too cold, too hot,...). The software implementation must be robust for these kinds of incidents.
Step 5: Validate of the digital twin in practice
The proof of the pudding is in the eating: to check whether a digital twin does as it is supposed to, it needs to be validated with real-world data. These data can be gathered in practice or through the use of an emulator of the real-world (a practice-like setup in the lab). Only after validation, can the digital twin be used for decision support.
What are the impacts that digital twins can have in fresh supply chains?
Digital twins are used to allow people to get an easy-to-grasp understanding of a complex system like a fresh supply chain. This is achieved by digitally mirroring a physical world to provide historical data, monitoring, and predictions of future states of a system. By utilizing digital twins in the postharvest setting, operators can be provided with a digital representation of agricultural postharvest activities which can be used to optimize the performance of the local processes.
Changes in the circumstances of the fresh products during their entire postharvest life can be simulated with the digital twin of the supply chain. Digital twins can translate sensor data and other metadata into actionable metrics on food quality, such as remaining postharvest life. For this idea, the information in the fresh supply chain is digitised and is linked to the available models and AI technology. Additionally, automated and intelligent decision support spanning multiple chain links can occur throughout this digital twin platform.

The effects are that logistics changes can be simulated, and the optimal decision on where a specific product batch should go to can be made. This will lead to less food waste, targeted quality in each market, happier customers and better product quality.
With the information from the physical supply chain available in a digital twin form, it becomes possible to do data-based troubleshooting and optimisation. Where does food quality loss occur? Where can the fresh supply chain be improved? Which changes will lead to which effects? How to build a sustainable supply chain and manage it?
As a third positive point, we postulate that working together as a supply chain, and better understanding how the postharvest handling in one part of the chain affects quality later on in the chain, will lead to higher trust, willingness for transparency, and more likely a fairer distribution of income in the chains where that is relevant.
Examples of digital twins in the fresh supply chain
Postharvest Storage, Sorting, Handling and Transportation
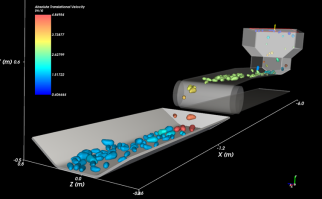
At all stages of the postharvest distribution process both quantitative and qualitative losses occur. Physical modelling is a useful and powerful tool to simulate how the handling of the product by a new piece of equipment may affect product quality. As an example, we have modelled a digital representation of a sorting belt. In this model, the effect of the mechanical process on bruising and puncturing can be shown. This gives an insight to engineers for improving and optimizing their design before fabrication. After fabrication, the digital representation can continue to be useful by linking it to sensoric data of the belt itself and of the potatoes transported, in order to build a digital twin that can be used for quality control and trouble shooting.
The Microclimate of Storage Boxes
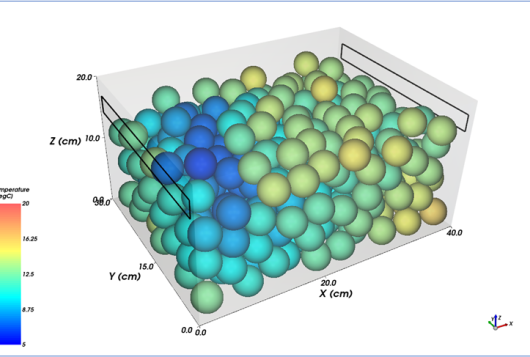
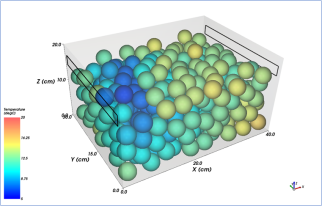
Perishable products need to stay in an uninterrupted cold chain during their postharvest life. When they are packed in a box, it is important to understand the microclimate inside the box to prevent temperature hotspots from occurring. With a CFD model, various options for the box design and the loading of the box can be simulated.
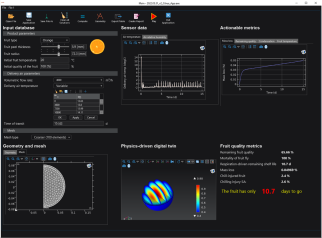
Postharvest Preservation of Fresh Fruits
Digital twins can be created for real-world entities at different scales in fresh supply chains, down to a single fruit. For instance, we developed a freely downloadable application, FruiTeD, which predicts how the state of the fruit evolves within a shipment based on measured air temperature data. The application has a physics-based model as its backbone. Users can input measured sensor data for air temperature in the vicinity of the fruit. The application upcycles these sensor data to obtain actionable metrics of fruit quality, such as remaining shelf life, chilling injury in the fruit or the net mass loss.